Premier Modèle : Leçons d’une Baseline à 32%
Secrets d’une matrice de confusion et enjeux des features manquantes
Aujourd'hui marque une étape cruciale pour le projet AstroSpectro : le premier entraînement de bout en bout de notre modèle de classification de types stellaires. Après avoir mis en place un pipeline robuste d'acquisition et de traitement pour 5000 spectres du relevé LAMOST DR5, il était temps de voir ce que notre première approche pouvait accomplir.
La Première Itération : Un Modèle Simple mais Honnête
Pour établir une baseline, l'objectif était de construire le modèle le plus simple possible afin de valider l'intégrité de la chaîne de traitement. La stratégie était la suivante :
- Modèle : Un
RandomForestClassifier, un algorithme robuste et bien compris. - Features : Uniquement quatre caractéristiques, basées sur la position des raies d'absorption les plus connues
Hα, Hβ, CaII H & K. Le but était de vérifier si cette information minimale contenait déjà un signal prédictif.
Le Résultat : Une Précision de 32%
Après entraînement et évaluation sur un jeu de test de 1250 spectres, le modèle a atteint une précision globale de 32%.
Ce score, bien qu'il semble modeste, est un point de départ extrêmement prometteur. Dans un problème de classification avec autant de classes A, B, C, F, G, K, M, N, s, une prédiction aléatoire n'obtiendrait qu'environ 9% de bonnes réponses. Notre score de 32% est donc plus de trois fois supérieur au hasard, ce qui prouve que notre pipeline fonctionne et que les features, même simples, contiennent un signal exploitable.
Voir les résultats en détail
Features utilisées pour l'entraînement : ['feature_Hα', 'feature_Hβ', 'feature_CaIIK', 'feature_CaIIH']
Nombre d'échantillons : 5000, Nombre de features : 4
Entraînement du modèle sur 3750 échantillons...
--- Rapport d'Évaluation ---
precision recall f1-score support
A 0.40 0.59 0.48 79
B 0.00 0.00 0.00 1
C 0.00 0.00 0.00 1
D 0.00 0.00 0.00 1
F 0.41 0.51 0.46 239
G 0.51 0.26 0.34 393
K 0.37 0.24 0.29 294
M 0.14 0.13 0.14 152
N 0.30 0.37 0.33 89
W 0.00 0.00 0.00 0
s 0.00 0.00 0.00 1
accuracy 0.32 1250
macro avg 0.19 0.19 0.18 1250
weighted avg 0.39 0.32 0.33 1250
Mais le plus intéressant n'est pas le score lui-même, mais ce que les erreurs du modèle nous apprennent.
L'Analyse : La Matrice de Confusion Parle
La matrice de confusion est une véritable carte de la "pensée" de notre modèle. Deux observations sautent aux yeux :
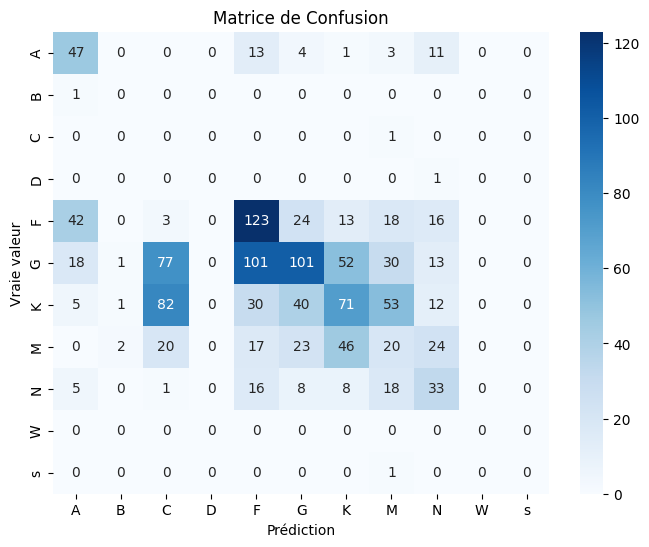
- Le Déséquilibre des Données : Le modèle est incapable de classer les étoiles de type
B, C, D ou s, car il n'en a vu qu'un seul exemple dans le jeu de test. C'est une leçon classique en IA : un modèle ne peut pas apprendre ce qu'il ne voit pas. - La "Confusion Physique" : Là où le modèle se trompe, il le fait de manière logique. Par exemple, il confond massivement les étoiles de type
Gavec les typesFetK. C'est normal : ces types sont adjacents dans la séquence spectrale et se ressemblent beaucoup. Le modèle a donc bien appris la "géographie" stellaire, mais il peine à tracer les frontières précises.
La Cause Racine : Le Problème des Features Manquantes
L'analyse de nos features extraites a révélé le cœur du problème. Un graphique montrant le pourcentage de valeurs nulles pour chaque feature est sans appel :
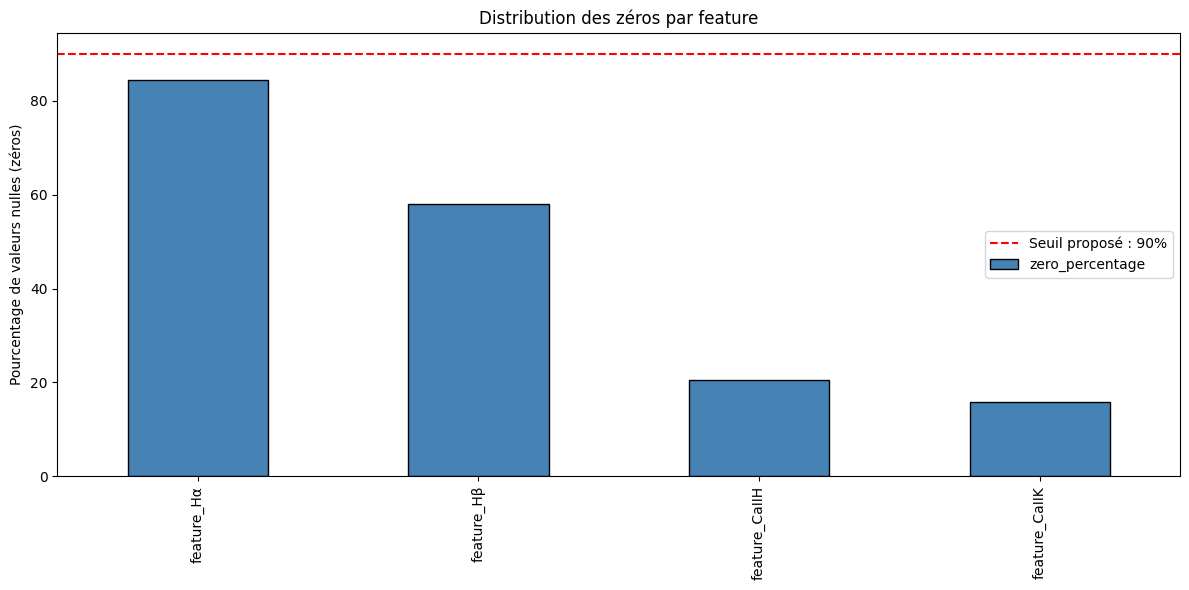
Ce graphique, qui analyse l'intégralité de notre dataset de 5000 spectres, montre une réalité surprenante : la feature basée sur la raie Hα est absente dans plus de 80% des cas. Les raies Hβ et CaII H/K sont, quant à elles, détectées plus fréquemment mais restent manquantes dans une part non négligeable des observations.
Le modèle a donc dû prendre ses décisions en se basant sur une information très lacunaire. Le fait d'atteindre 32% dans ces conditions est la preuve que les raies du calcium et Hβ sont des indicateurs puissants, mais que le modèle est fortement handicapé par la difficulté à extraire un signal clair pour Hα avec les paramètres actuels.
Les Prochaines Étapes : La Chasse aux Vraies Features est Ouverte !
Ce premier résultat n'est pas une fin, mais un point de départ documenté. La feuille de route pour la prochaine itération est claire : nous devons fournir des "ingrédients" de meilleure qualité à notre modèle.
- Mesurer la Force, pas la Présence : La prochaine version du pipeline ne se contentera plus de savoir si une raie est là, mais mesurera sa profondeur (via la
prominencedes pics). C'est une information physique beaucoup plus riche. - Créer des Features de Ratio : Nous allons calculer les ratios entre les profondeurs de différentes raies. Ces ratios sont des indicateurs de température bien connus en astrophysique et devraient aider le modèle à mieux distinguer les classes adjacentes (comme
F, G et K). - Nettoyer le Dataset : Pour la prochaine évaluation, nous nous concentrerons sur les classes pour lesquelles nous avons un nombre suffisant d'exemples
A, F, G, K, Mafin d'obtenir des métriques de performance plus fiables et interprétables.
Cette baseline de 32% est la fondation sur laquelle nous allons construire. Chaque amélioration future pourra être mesurée par rapport à ce point de départ, démontrant l'impact direct de notre travail de feature engineering.
Restez à l'écoute !